
Betreibst Du eine große Website, mit hunderten oder tausenden Unterseiten und hast Probleme bei der Indexierung Deiner Inhalte?
Dann könnte es sein, dass Du Schwierigkeiten mit dem Crawlbudget hast.
Was das genau ist und wie Du es optimieren kannst, erfährst Du in diesem Artikel.
Was ist das „Crawl Budget“?
Das Crawl Budget definiert die Anzahl der Seiten, die Suchmaschinen innerhalb eines bestimmten Zeitraums auf Deiner Website crawlen und indexieren. Es stellt sozusagen das Zeitkontingent dar, das Suchmaschinen-Crawler Deiner Website widmen.
Das Crawl Budget setzt sich aus zwei Hauptfaktoren zusammen:
Crawl-Limit/Host-Last: Dieser Faktor bezieht sich auf die technische Kapazität Ihrer Website, Crawler-Anfragen zu verarbeiten. Google möchte Websites nicht überlasten und passt daher die Crawling-Intensität entsprechend an. Faktoren wie Serverleistung, Ladezeiten und Fehlerraten spielen hier eine entscheidende Rolle.
Crawl-Nachfrage/Crawl-Planung: Hierbei geht es um die Relevanz und Priorität Ihrer Seiten aus Sicht der Suchmaschine. Seiten mit höherer Autorität (durch interne und externe Links), regelmäßigen Updates und höherer Beliebtheit werden häufiger gecrawlt.
Suchmaschinen bestimmen das Crawl Budget einer Website anhand verschiedener Faktoren, darunter:
- Die Popularität der Website, gemessen an Backlinks und Nutzerinteraktionen
- Die Frequenz von Inhaltsänderungen und -aktualisierungen
- Die Server-Performance und Antwortzeiten
- Die Qualität der Inhalte und deren Einzigartigkeit
- Die strukturelle Integrität der Website (Fehler, Weiterleitungen, etc.)
Übrigens: Websites, die auf einem gemeinsamen Host untergebracht sind, teilen sich das Crawl Budget des Hosts. Dies kann insbesondere bei günstigen Shared-Hosting-Angeboten zu Einschränkungen führen.
Wann ist das Crawl Budget relevant für mich?
Betreibst Du eine kleinere Website, kannst Du hier abbrechen. Dann wird das Crawlbudget keine Rolle spielen.
Wichtig wird es erst bei größeren Websites mit mehreren Tausend URLs. Je umfangreicher eine Website ist, desto wahrscheinlicher ist es, dass das Crawl Budget zum limitierenden Faktor wird. E-Commerce-Plattformen mit tausenden von Produktseiten, Varianten und Filteroptionen sind hier besonders gefährdet.
Häufige Ursachen für Crawl Budget Verschwendung
URLs mit Parametern und Crawler-Fallen: Dynamisch generierte URLs mit zahlreichen Parametern, wie sie oft bei Filtern oder Sortieroptionen in Online-Shops vorkommen, können zu einer praktisch unbegrenzten Anzahl von URLs führen. Diese „Crawler-Fallen“ können einen Großteil Ihres Crawl Budgets verschlingen.
Duplicate Content: Wenn ähnliche oder identische Inhalte unter verschiedenen URLs zugänglich sind (z.B. durch unterschiedliche Domain-Varianten wie www/non-www oder HTTP/HTTPS), verschwendet Google wertvolles Crawl Budget mit dem Crawlen redundanter Inhalte.
Minderwertige Inhalte: Seiten mit geringem Mehrwert, wie dünne Inhalte oder automatisch generierte Seiten, verbrauchen Crawl Budget, ohne einen signifikanten SEO-Nutzen zu bieten.
Fehlerhafte und weiterleitende Links: Jeder fehlerhafte Link oder jede Weiterleitung kostet Crawl Budget. Insbesondere Weiterleitungsketten (mehrere aufeinanderfolgende Redirects) sind problematisch.
Falsche Einträge in XML-Sitemaps: Wenn Ihre XML-Sitemap fehlerhafte URLs, nicht-indexierbare Seiten oder Weiterleitungen enthält, führt dies zu ineffizientem Crawling.
Langsame Ladezeiten und Timeouts: Langsame Server-Antwortzeiten bedeuten, dass Crawler mehr Zeit für jede Seite benötigen, was die Anzahl der gecrawlten Seiten reduziert.
Hohe Anzahl nicht-indexierbarer Seiten: Wenn viele Seiten mit noindex-Tags oder in der robots.txt blockierte Bereiche für Crawler zugänglich sind, wird Crawl Budget verschwendet.
Mangelhafte interne Linkstruktur: Eine schlechte interne Verlinkung kann dazu führen, dass wichtige Seiten zu wenig Crawling-Aufmerksamkeit erhalten, während unwichtigere Seiten überproportional oft gecrawlt werden.
Analyse des aktuellen Crawl Budgets
Bevor Du Optimierungsmaßnahmen ergreifst, solltest Du Dein aktuelles Crawl Budget analysieren. Dafür stehen verschiedene Tools zur Verfügung:
Google Search Console (GSC): In der GSC findest Du unter dem Menüpunkt „Crawling“ Statistiken darüber, wie oft und wie viele Seiten Ihrer Website von Googlebot besucht werden. Diese Daten geben einen ersten Einblick in das Crawl Budget.
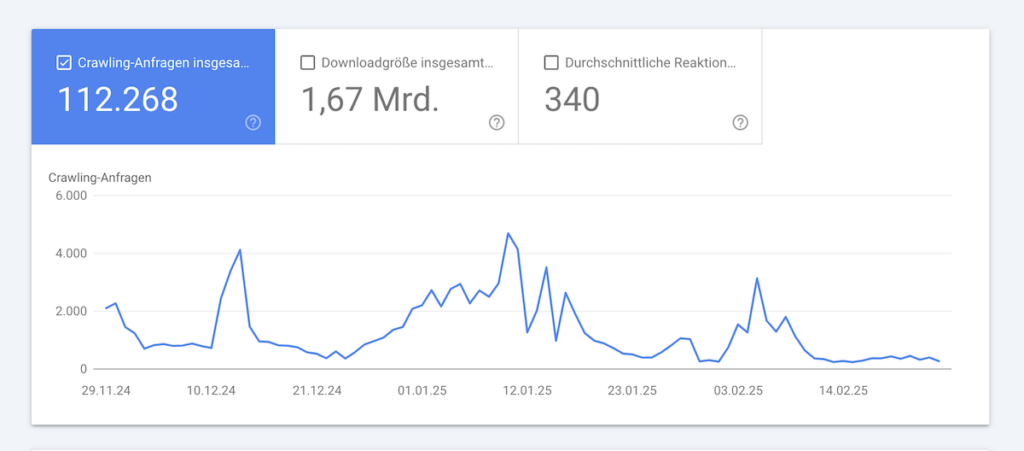
Server-Logfile-Analyse: Die detailliertesten Informationen erhalten Sie durch die Analyse Ihrer Server-Logfiles. Hier können Sie genau sehen, welche Seiten von welchen Crawlern wie oft besucht werden. Tools wie Screaming Frog Log File Analyzer oder Botify können diese Analyse erheblich erleichtern.
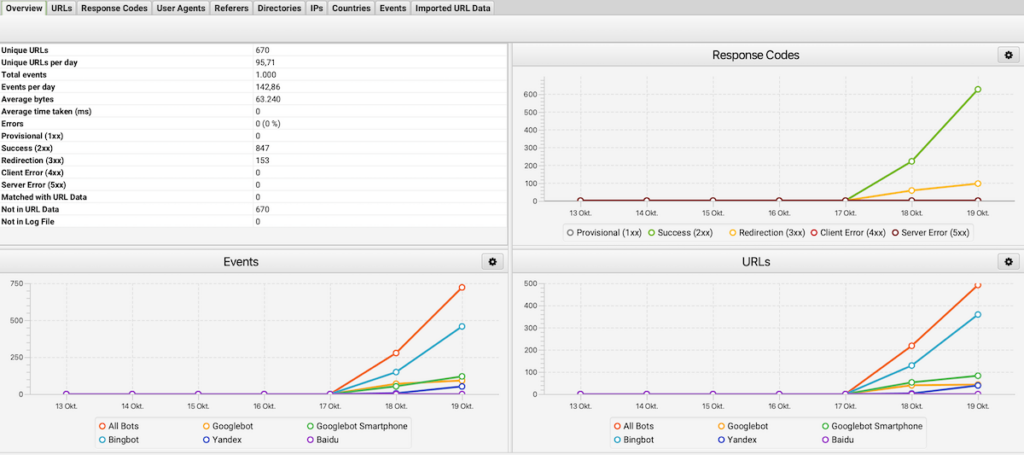
Bei der Analyse sind folgende Metriken interessant:
- Die durchschnittliche Anzahl der täglich gecrawlten Seiten
- Die Verteilung des Crawlings auf verschiedene Seitenbereiche
- Muster und Regelmäßigkeiten im Crawling-Verhalten
- Seiten, die sehr häufig oder sehr selten gecrawlt werden
- Fehler und Weiterleitungen, die beim Crawling auftreten
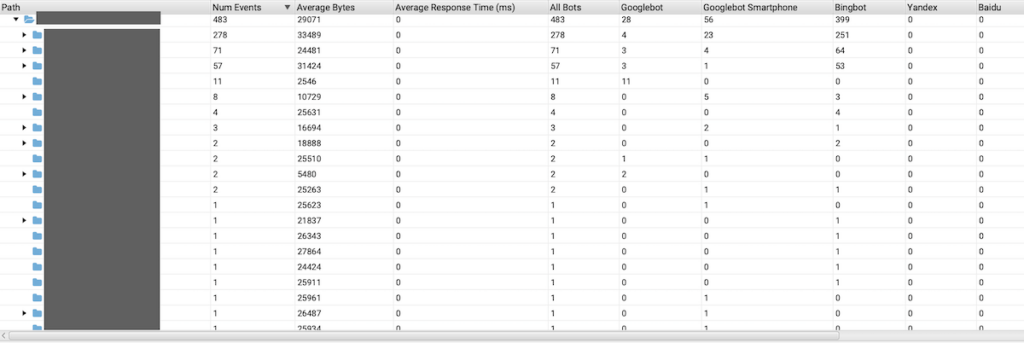
Probleme mit dem Crawl Budget zeigen sich oft durch:
- Große Diskrepanzen zwischen der Anzahl Ihrer Seiten und der Anzahl gecrawlter Seiten
- Einen hohen Anteil an Fehlern oder Weiterleitungen in den Crawling-Statistiken
- Lange Zeiträume zwischen dem Hinzufügen neuer Seiten und deren Indexierung
- Ungleiche Verteilung des Crawlings (z.B. werden bestimmte Bereiche vernachlässigt)
Maßnahmen zur Optimierung des Crawlbudgets
Technische Optimierungsmaßnahmen
Einsatz von robots.txt zur Steuerung des Crawlings & Blockieren von URLs mit Parametern
Definiere in der robots.txt, welche Bereiche der Website von Suchmaschinen nicht gecrawlt werden sollen. Beispielsweise kannst Du den Zugriff auf Admin-Bereiche oder Testseiten verhindern:
User-agent: *
Disallow: /admin/
Disallow: /test/Vermeide Crawling von URLs, die dynamische Parameter enthalten, indem Du entsprechende Regeln in der robots.txt festlegst. Beispiel:
User-agent: *
Disallow: /*?sort=Sitemap aktuell halten
Erstellen eine übersichtliche XML-Sitemap, die nur relevante URLs enthält. Achte darauf, dass die Sitemap regelmäßig aktualisiert und in der Google Search Console eingereicht wird.
Hinweis: Bearbeite Deine robots.txt nur, wenn Du verstehst, was Du hier tust. Im schlimmsten Fall blockst Du das Crawling von wichtigen Website Bereichen. Im Zweifelsfall hole Dir lieber einen Experten dazu.
Steigerung der Ladegeschwindigkeit
Optimiere Bilder, komprimiere Dateien und nutze moderne Formate (z. B. WebP), um die Ladezeiten zu reduzieren.
Server-Ressourcen optimieren
Überprüfe Deine Serverauslastung und stelle sicher, dass ausreichend Ressourcen zur Verfügung stehen. Eine skalierbare Hosting-Lösung oder die Nutzung von Managed-Hosting-Diensten kann hier helfen.
Caching-Strategien implementieren
Setze auf Browser- und Server-Caching, um wiederkehrende Anfragen effizient zu bedienen.
Reduzierung von JavaScript und CSS
Minimiere den Einsatz von übermäßigem JavaScript und CSS, indem Du unnötige Skripte entfernst oder zusammenfasst. Tools wie CSS Minifier oder UglifyJS können Dir dabei helfen.
CDN-Nutzung zur Entlastung des Servers
Integriere ein Content Delivery Network (CDN), um statische Inhalte wie Bilder, Videos und Skripte von einem global verteilten Netzwerk bereitzustellen. Dies reduziert die Serverlast und verbessert die Ladezeiten insbesondere für internationale Nutzer.
Inhaltliche Optimierungsmaßnahmen
Beheben von Duplicate Content
Nutze kanonische Tags (<link rel=“canonical“ href=“https://www.beispiel.de/seite“>), um doppelte Inhalte zu kennzeichnen. Entferne überflüssige Varianten und führe 301-Weiterleitungen bei zusammengeführten Seiten ein.
Verbesserung der internen Linkstruktur
Verlinke wichtige Seiten prominent innerhalb der Website. Setze sprechende, keywordreiche Ankertexte.
Implementierung einer flachen Website-Architektur
Reduziere die Klicktiefe, indem Du Hauptkategorien direkt von der Startseite verlinkst. Eine flache Architektur bedeutet, dass auch tiefere Seiten in wenigen Schritten erreichbar sind. Dies erleichtert dem Crawler das Auffinden und Indexieren von Inhalten.
Vermeidung von verwaisten Seiten (Orphan Pages)
Stelle zudem sicher, dass jede Seite mindestens einen internen Link erhält. Aktuell verwaiste Seiten kannst Du ebenfalls mit dem Screamingfrog oder SEO Suites wie SEMrush finden.
Zusammenfassung
Die Optimierung des Crawl Budgets ist ein oft übersehener, aber für größere Websites entscheidender Aspekt der technischen SEO. Durch die gezielte Verbesserung der technischen Grundlagen, die Beseitigung von Crawling-Hindernissen und die strategische Priorisierung wichtiger Inhalte kannst Du sicherstellen, dass Suchmaschinen die wertvollsten Teile Deiner Website effizient crawlen und indexieren.
Ein systematischer Implementierungsplan für die Crawl-Budget-Optimierung sollte folgende Schritte umfassen:
- Analyse: Erfasse des Status quo durch Log-File-Analyse und GSC-Auswertung
- Problembehebung: Beseitigung technischer Probleme und Crawling-Hindernisse
- Strukturverbesserung: Optimierung der Website-Architektur und internen Verlinkung
- Performance-Optimierung: Verbesserung der Server-Leistung und Ladezeiten

